

 收藏
收藏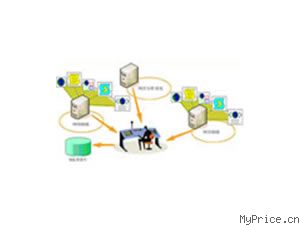





1、功能强大、高效的网络蜘蛛
高效的网络蜘蛛抓取引擎,Web Spider单引擎效率达到200万(URL)/天。采用多互联网入口(URL)、多层次、多线程并发抓取。自动分析和提取提取网页链接,使网络蜘蛛能够高效渗入互联网 。
2、能化的网页内容分析和提取
采用目前最先进分词技术、短语识别技术,实现网页内容的高效、准确的分析提取。获取特定网址的网页内容,基于搜索引擎,获取与特定关键词相关的网页内容。Web Analyse的分析效率达到500万页面/天。
3、完善的分析统计平台
针对分析提取的内容,按照用户需求可进行各种统计分析,形成用户所需的分析统计报告。
4、B/S与C/S相结合的分布式架构
系统采用B/S与C/S相结合,用户可随时随地通过IE浏览器进行远程浏览和操作网页抓取结果和分析结果。也可通过客户端软件控制网络蜘蛛的抓取进度和网页分析的进度。通过分布式架构可以实现网络蜘蛛和网页分析构件的并发处理和集中管理,大大提高了网页抓取和分析的数量和速度,使大规模网页内容抓取和分析成为可能。
5、稳定的系统运行
系统具有自我监控、诊断、自动恢复重启功能,充分保障网络蜘蛛和网页分析系统的长时间稳定连续的运行。
6、友善、便捷的用户界面
系统是基于Window平台的分布式的网络工具,采用全中文界面,界面美观,操作简单,方便用户自行定义各种功能配置,整个工具的管理界面更加人性化。
7、轻松简单的二次开发
系统系统基于.Net平台,采用面向对象的设计开发方式,构建高聚合、低耦合的代码模块,便于系统的模块修改升级;提供开发式API接口和高度模块化设计,十分方便与其它系统实现无缝集成,从而实现资源整合,构建更加完善的用户系统。


